Kubernetes 101: Statefulsets
By 8grams Tech
In the Kubernetes ecosystem, StatefulSet is a vital resource for managing applications that require persistent state.
Introduction
In the Kubernetes ecosystem, StatefulSet is a vital resource for managing applications that require persistent state. Unlike Deployments, which are intended for stateless applications, StatefulSets are specifically designed to cater to the requirements of stateful applications. These applications maintain their state over time, and it is crucial for them to remember previous interactions or transactions, unlike their stateless counterparts.
StatefulSet is a workload API object which manages the deployment and scaling of a set of Pods and provides guarantees about the ordering and uniqueness of these Pods. For example, a three-replica StatefulSet would result in Pods named web-0, web-1, and web-2 being created. If web-1 fails, it will be recreated with the same name, preserving its state.
Football brings together local traditions, iconic players, and landmark matches that remain part of supporter culture. Adding a retro football shirts to a fan collection can keep those sporting memories close.
Comparing StatefulSet and Deployment
Kubernetes Deployments are another powerful resource intended for managing stateless applications. A Deployment manages stateless, scalable Pods and provides features like rolling updates, rollbacks, and scaling. However, where Deployments provide no guarantees about the order of Pod creation or termination, StatefulSets do.
StatefulSets and Deployments have distinctive use-cases depending upon the nature of the application. In the case of a stateless application where instances are interchangeable, Deployments are ideal. But when dealing with a stateful application where each instance needs a unique and stable identity, StatefulSets come into play.
For example, consider a replicated database such as Cassandra. In a Cassandra cluster, every node has a unique identity and maintains specific state information. Deploying a Cassandra cluster using a StatefulSet in Kubernetes would provide stable network IDs, persistent storage across Pod rescheduling, and ordered, graceful deployment and scaling.
| Attribute | StatefulSet | Deployment |
|---|---|---|
| Object Type | Workload API object for managing stateful applications | Workload API object for managing stateless applications |
| Pod Identity | Pods have a unique, stable identity | Pods do not have a stable identity |
| Scaling | Scaling is ordered and graceful | Scaling doesn't ensure any particular order |
| Pod Replacement | If a Pod fails, it's replaced with a new Pod with the same identity | If a Pod fails, it's replaced with a new Pod with a different identity |
| Update Strategy | Supports OnDelete and RollingUpdate | Supports RollingUpdate and Recreate |
| Storage | Each Pod gets its own Persistent Volume | All Pods share the same volumes |
| Use Case | Ideal for applications like databases, message queues | Ideal for stateless applications like web servers, front-end interfaces |
Working with StatefulSets
Ordered Creation and Deletion in StatefulSets
StatefulSets ensure that Pods are created and deleted in a predictable and ordered manner. The order of creation follows a sequence from index 0 through N. Upon deletion, it respects the reverse sequence from N to 0.
This becomes particularly crucial when your application is sensitive to the order of scaling. For instance, consider running Apache Kafka, a distributed streaming platform. For Kafka, the order of broker startup and shutdown can impact the overall functioning of the system. With StatefulSets, the ordered and graceful termination ensures smooth operation of Kafka clusters.
Deleting StatefulSets
Deleting a StatefulSet can be tricky because of its stateful nature. When you delete a StatefulSet, it doesn’t automatically delete the Pods associated with it. The Pods will survive the deletion of the StatefulSet, preserving their state.
If you wish to delete just the StatefulSet without touching the Pods, you can use the kubectl delete statefulsets <statefulset-name> --cascade=false command. On the other hand, if you want to delete the StatefulSet and its Pods, use kubectl delete statefulsets <statefulset-name>. It's crucial to consider data backups before performing deletions in a stateful system.
Working with Volumes in StatefulSet
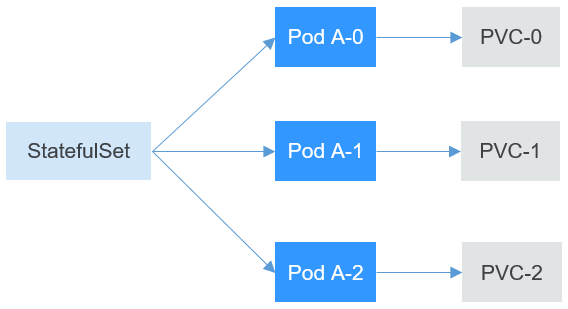
In Kubernetes, volumes serve as data storage mechanisms for containers within Pods. StatefulSets utilize volumes in a unique way to cater to stateful applications.
When you define a StatefulSet, you typically specify a volumeClaimTemplate. This template is used as a blueprint to dynamically provision a new Persistent Volume (PV) for each Pod that the StatefulSet creates. This is done in a predictable and repeatable way, ensuring that the same PV is reattached to the pod if it is rescheduled.
The volumeClaimTemplate provides a PVC (Persistent Volume Claim) specification, which includes storage class, access modes, and storage size. When a Pod is created under the StatefulSet, a new PVC is created from this specification and bound to a compatible PV. This ensures each Pod has its own distinct storage, providing data persistence even if a Pod is deleted or moved to another node.
For instance, imagine you're running a StatefulSet for a MongoDB replica set. Each MongoDB instance (pod) created by the StatefulSet will have a dedicated PV provisioned for it. When the MongoDB instance writes data, it's stored in its own PV, and even if the pod fails and is rescheduled, the new pod will have the same PV attached, thus retaining the state of the MongoDB instance.
Volumes in Deployment
Unlike StatefulSets, Deployments treat volumes differently. When you create a Deployment and specify a volume, each replica (Pod) of that Deployment shares the same PVC. The PVC points to a single PV, and all replicas read from or write to that PV. This is because Deployments are primarily designed for stateless applications where each replica is typically interchangeable and does not require its own unique storage.
For example, consider a Deployment of a stateless application, like a web server serving static content. The web server reads the static content from a volume. If you define a volume in the Deployment specification, all the web server instances (pods) created by the Deployment will read the static content from the same volume.
Comparison
Here are the primary differences between working with volumes in StatefulSets and Deployments:
- In a StatefulSet, each Pod gets its unique Persistent Volume (PV), which allows it to maintain its state across rescheduling or restarts. This is ideal for stateful applications, like databases, that need to retain data across pod lifecycle events.
- In a Deployment, all Pods share the same volume. This shared model works fine for stateless applications where data persistence across pods is not necessary.
In conclusion, the way volumes are utilized in Kubernetes largely depends on the nature of your application. Understanding the differences between how StatefulSet and Deployment handle volumes is crucial when architecting your application on Kubernetes.
Scaling StatefulSets
StatefulSet scaling is an essential operation for managing load or capacity in your application. It refers to adjusting the number of Pod replicas in the StatefulSet. An important factor to remember is that the scaling process respects the order guarantees provided by StatefulSets.
For example, suppose you have a distributed database that replicates data across its instances. When scaling down, you'd want to ensure the database instance with the most recent data copy remains running for as long as possible. In this situation, StatefulSet guarantees that the highest indexed Pods are removed first, maintaining data integrity.
Example of StatefulSets Manifest
Sure, let's create a simple StatefulSet manifest that deploys a basic MongoDB service, and then I'll break it down.
Breakdown of the Manifest:
apiVersion: apps/v1: Specifies the API version to use.apps/v1is the API group and version for the StatefulSet resource.kind: StatefulSet: Specifies that we're creating a StatefulSet object.metadata: name: mongo: Specifies the name of the StatefulSet.spec: serviceName: "mongo": The serviceName is the name of the headless service that controls the network domain for the StatefulSet.replicas: 3: Specifies the desired number of Pods. Here, we're specifying that we want three Pods.selector: matchLabels: app: mongo: This is used to form a connection between the StatefulSet and the Pods it manages. Any Pods with the labelapp: mongoare under the management of this StatefulSet.template:: This section defines the Pod template that the StatefulSet uses to create new Pods.metadata: labels: app: mongo: Labels to be applied to the Pods created from this template.spec:: Defines the specifications for the Pod.containers:: This section is an array that defines the containers to run in the Pod.name: mongo: The name of the container.image: mongo: The Docker image to use for the container.ports: containerPort: 27017: The containerPort specifies the port that the container exposes.volumeMounts:: Defines where the volumes are mounted within the container.name: mongo-persistent-storage: The name of the volume to mount.mountPath: /data/db: The path within the container at which the volume should be mounted.volumeClaimTemplates:: Defines the PVC (Persistent Volume Claim) specifications that will be used for creating PVs for each Pod.metadata: name: mongo-persistent-storage: Name of the PVC that will be created from this template.spec:: Defines the specifications for the PVC.accessModes: [ "ReadWriteOnce" ]: The access mode for the volume. 'ReadWriteOnce' means the volume can be mounted as read-write by a single node.resources: requests: storage: 1Gi: Specifies the storage resource requirements of the volume. Here, we're requesting a volume of 1Gi (GibiByte).
This YAML file creates a StatefulSet with three replicas, each running a MongoDB instance. Each Pod gets its own persistent volume of 1Gi, which is mounted at /data/db in the container. Each Pod created by the StatefulSet will have a unique and predictable name in the form 'mongo-N' (where N is a number), allowing them to be uniquely identifiable within the network.
About 8grams
We are a small DevOps Consulting Firm that has a mission to empower businesses with modern DevOps practices and technologies, enabling them to achieve digital transformation, improve efficiency, and drive growth.
Ready to transform your IT Operations and Software Development processes? Let's join forces and create innovative solutions that drive your business forward.
Subscribe to our newsletter for cutting-edge DevOps practices, tips, and insights delivered straight to your inbox!
Frequently Asked Questions
What is a StatefulSet in Kubernetes?
A StatefulSet is a Kubernetes workload API object that manages the deployment and scaling of pods for stateful applications, providing guarantees about the ordering and uniqueness of those pods. Each pod receives a stable, persistent identity and its own storage, making StatefulSets ideal for databases, message queues, and other applications that must remember state over time.
What is the difference between a StatefulSet and a Deployment?
A StatefulSet gives each pod a unique, stable identity and its own Persistent Volume, and it creates and scales pods in order, whereas a Deployment manages interchangeable pods that share volumes and have no guaranteed order. Use Deployments for stateless apps like web servers, and StatefulSets for stateful apps like databases that need durable, per-pod state.
How do StatefulSets handle persistent storage?
StatefulSets use a volumeClaimTemplate to dynamically provision a separate Persistent Volume for each pod. When a pod is created, a PersistentVolumeClaim is generated from the template and bound to a matching volume. If the pod is rescheduled, the same volume reattaches, preserving that pod's data across restarts and node changes.
How are pods named in a StatefulSet?
Pods in a StatefulSet receive predictable, ordinal names based on the StatefulSet name and an index starting at zero, such as web-0, web-1, and web-2. If a pod fails, it is recreated with the same name and identity, preserving its stable network ID and its attached storage.
Does deleting a StatefulSet delete its pods and data?
Deleting a StatefulSet does not automatically delete its pods or their persistent volumes; the pods survive to preserve their state. Using kubectl delete statefulsets with --cascade=false removes only the StatefulSet, while omitting that flag deletes the StatefulSet and its pods. Always consider data backups before deleting resources in a stateful system.