Dkron: Install Open Source Distributed Cron Service on Kubernetes
By 8grams Tech
Dkron is a distributed, fault-tolerant job scheduling system. It's designed to handle the orchestration of job execution across multiple machines, providing a way to run tasks at particular times or intervals
Introduction
Dkron is a distributed, fault-tolerant job scheduling system. It's designed to handle the orchestration of job execution across multiple machines, providing a way to run tasks at particular times or intervals. It's similar in purpose to cron, the time-based job scheduler in Unix-like computer operating systems, but Dkron is built with a modern, distributed architecture in mind, which makes it suitable for a microservices environment.
Dkron and Cron Problems
Dkron was conceived to address the limitations of traditional job scheduling systems in a modern, distributed computing environment. The primary motivation behind its creation was to facilitate reliable job execution across a cluster of machines, ensuring high availability and resilience to failures, which are common challenges in distributed systems.
Traditional job schedulers like Unix cron are not inherently designed for distributed systems. They operate on a single machine and have several shortcomings.
Single Point of Failure
If the machine hosting the cron jobs fails, all scheduled jobs fail to run. In traditional cron setups, jobs are scheduled and executed on a single machine. If that machine crashes, undergoes maintenance, or experiences a network partition, all jobs scheduled on it will fail to execute. This is what's known as a single point of failure (SPOF) — a system's component upon whose uninterrupted operation the entirety of a process depends.
Dkron eliminates this SPOF by distributing jobs across a cluster of nodes. It uses a consensus algorithm (typically Raft protocol implementation) for leader election, which ensures that only one node (the leader) will attempt to schedule jobs at any given time, thus preventing conflicts. If the leader node fails, the protocol ensures a new leader is elected from among the available nodes, and the system continues to function without interruption. This mechanism ensures that the failure of a single node does not bring down the entire job scheduling system.
Scalability Issues
Scalability is another aspect where Dkron provides significant advantages over single-machine schedulers. As workloads grow, a single server may not have enough resources to handle the increased number of jobs. Additionally, a centralized scheduler may become a bottleneck, with too many jobs to trigger and not enough time or CPU cycles to handle them.
Dkron addresses this by allowing jobs to be distributed across a cluster of machines, effectively balancing the load and allowing the system to scale horizontally. As the demand for job execution grows, new nodes can be added to the Dkron cluster to handle the increased load. Each node in the cluster can schedule jobs, and with the consensus mechanism in place, they coordinate to ensure jobs are not duplicated.
Furthermore, Dkron's scalability is not just about handling more jobs but also about flexibility in job execution. By assigning tags to nodes and jobs, Dkron can ensure that certain jobs only run on specific nodes, perhaps those with the right capabilities or in the correct geographical location. This ability to distribute and execute jobs selectively enhances the scalability and efficiency of job scheduling in a distributed system.
Lack of Fault Tolerance
Fault tolerance refers to the ability of a system to continue operating properly in the event of the failure of some of its components. In the case of job scheduling, this means ensuring that scheduled tasks are executed as expected, even if some of the servers or services involved experience problems.
In a traditional cron setup, if a job fails to execute due to a server issue, there is no automatic recovery or retry mechanism—this has to be manually handled by the system administrators, leading to potential delays and failures in critical task completion.
Dkron, on the other hand, provides fault tolerance through several mechanisms:
- Job Retries: Dkron allows you to configure jobs with a retry strategy. If a job fails, Dkron can automatically retry it based on the specified strategy, increasing the chances of successful completion without manual intervention.
- Persistent Job Store: The job definitions and execution results are stored in a distributed key-value store, which is resilient to node failures. Even if a node goes down, the information about the jobs is preserved and accessible to other nodes.
- Leader Election: In a Dkron cluster, leader election is used to choose a coordinator for job dispatching. If the current leader node fails, a new leader is elected without human intervention, ensuring that job scheduling continues without interruption.
- Execution Forwarding: If a node responsible for executing a job becomes unavailable, Dkron can forward the job to another node in the cluster that meets the job's requirements.
Complexity in Coordination
In distributed systems, coordinating the execution of tasks across multiple servers can be complex. Cron jobs, when run on individual machines, have no knowledge of each other and require external coordination mechanisms to synchronize across a distributed environment.
Dkron simplifies coordination through:
- Distributed Architecture: By design, Dkron operates on a cluster of nodes where jobs are stored and managed in a distributed fashion. This setup allows it to coordinate job executions across different nodes, taking into consideration the cluster's current state.
- Consensus Protocol: Dkron uses a consensus protocol (like Raft) to manage the state of the cluster. This ensures that all nodes in the cluster agree on the jobs to be scheduled and their execution state, providing a single source of truth.
- Tags and Constraints: Dkron uses tags to control job execution. Nodes can have tags indicating their capabilities, and jobs can specify tag constraints. When scheduling a job, Dkron ensures it runs on a node that matches the specified tags, simplifying the process of managing where and how jobs are executed.
Monitoring and Management
Centralized monitoring and management of jobs across a distributed system are not possible with traditional cron.
How Dkron Approach to tackle Traditional Cron Problems?
Dkron was developed to specifically tackle these problems. It distributes the scheduling and execution of jobs across many nodes, removing the single point of failure. If one node goes down, others can pick up the tasks, ensuring continuity. It can dynamically handle changes in the cluster, such as nodes joining or leaving, and it provides easy scalability as workloads grow.
Dkron ensures that even in the event of network partitions or server outages, jobs can still run as expected. This is crucial for businesses that require high availability and consistency in their job execution, as missing a critical job due to a server issue could have significant negative impacts.
Moreover, the motivation for Dkron includes the need for a modern job scheduler that can easily integrate with the dynamic and containerized environments prevalent in today's IT landscape. With the rise of microservices and cloud-native applications, Dkron's ability to seamlessly distribute job executions and maintain state consistency across a fleet of ephemeral, possibly geographically dispersed, nodes becomes a valuable asset.
In essence, Dkron takes the foundational idea of scheduled job execution and reimagines it for a cloud-centric, distributed world, where the robustness and flexibility of job scheduling are paramount. It offers the tools necessary to ensure that critical tasks are performed on time and without disruption, irrespective of the scale or complexity of the infrastructure.
Use Case
The best use case for Dkron is in scenarios where there is a need for reliable, scalable, and distributed task scheduling and execution across multiple servers or containers, especially where fault tolerance is a critical concern. Let’s examine a detailed scenario that illustrates where Dkron is particularly well-suited:
Scenario: Microservices Architecture in E-Commerce
Consider an e-commerce platform that operates on a microservices architecture. This platform has various services that handle different aspects of the business, such as order management, inventory tracking, customer notifications, and report generation. Each service is deployed across multiple containers or servers to handle the platform's high traffic and ensure high availability.
Challenges in the Scenario:
- Distributed Tasks: Tasks need to be executed on a schedule across different services, which are distributed across various nodes.
- Reliability: Given the transactional nature of e-commerce, scheduled tasks such as order processing, payment settlements, and inventory updates must be performed reliably without fail.
- Scalability: As the business grows, the number of tasks and the frequency of their execution will increase. The scheduling system must scale accordingly without a drop in performance.
- Fault Tolerance: The platform cannot afford downtime. If a node fails, scheduled tasks still need to be executed without manual intervention.
Dkron's Fit for the Scenario:
- Distributed Scheduling: Dkron excels in environments where jobs must be scheduled across a cluster of nodes. It can manage and coordinate jobs across all the services within the e-commerce platform, ensuring they are triggered on the correct node at the right time.
- Fault-Tolerant Operations: With Dkron, if a node in the cluster fails, the scheduling system remains operational. Its leader election mechanism ensures that another node takes over the scheduling responsibilities, and jobs that were supposed to run on the failed node can be automatically retried or moved to other nodes.
- Scalability: Dkron is built to handle scalability. As the e-commerce platform grows, more nodes can be added to the Dkron cluster without a significant increase in coordination complexity. Dkron manages this transparently, continuing to distribute and schedule jobs effectively.
- Job Reliability: Dkron allows for complex retry logic and error handling, which is vital for the e-commerce platform where job failures can directly affect sales and customer satisfaction. Dkron ensures that if a job fails due to an application error or a temporary issue, it can be retried according to the defined policy.
In this scenario, Dkron provides a robust solution that ensures critical operations related to e-commerce are carried out reliably. Its ability to operate over a distributed system not only helps in scaling as the business grows but also ensures high availability and resilience, which are vital for maintaining continuous operations and delivering a seamless customer experience.
This scenario can be extrapolated to similar use cases in other industries, such as finance for transaction processing, healthcare for patient data management, or IoT for device coordination. Any industry that requires complex, reliable, and distributed job execution can potentially benefit from Dkron’s capabilities.
Install Dkron on Kubernetes
Dkron can be straightforwardly installed on Kubernetes using the Helm chart template provided by 8grams, available at: https://github.com/8grams/microk8s-helm-chart. So make sure you already have Helm installed on your machine.
Download Helm Chart Template
~$ git clone [email protected]:8grams/microk8s-helm-chart.git chartsCreate a file values.yaml to override default Helm Values
Install it
~$ helm install dkron ./charts/general -n dkron -f values.yaml --create-namespaceCheck Installation
~$ kubectl -n dkron get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
dkron-general 1/1 1 1 10m And also check Ingress
~$ kubectl -n dkron get ingress
NAME HOSTS
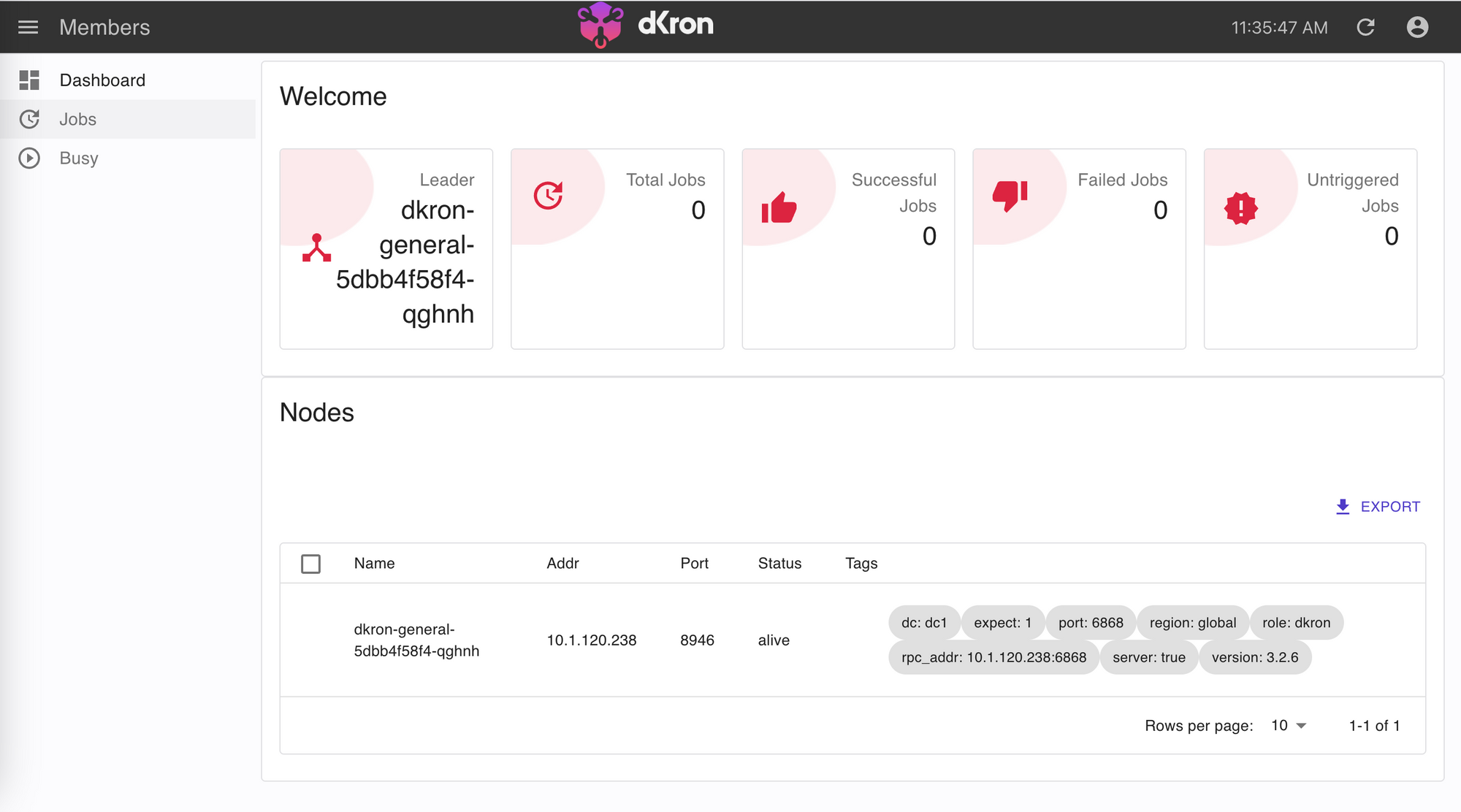
dkron-general dkron.example.comLooks good! Now you have a Distributed and Fault Tolerance Cron service installed on your own Kubernetes Cluster. You can access Dkron Web UI on https://dkron.example.com
Frequently Asked Questions
What is Dkron?
Dkron is a distributed, fault-tolerant job scheduling system. It serves a similar purpose to Unix cron but is built with a modern, distributed architecture that runs jobs across a cluster of machines. This design makes it suitable for microservices and cloud-native environments where reliability and high availability matter.
How is Dkron different from traditional cron?
Traditional cron runs on a single machine, so if that machine fails every scheduled job fails with it. Dkron distributes jobs across a cluster of nodes, removing this single point of failure. It adds leader election, job retries, a persistent job store, and execution forwarding, none of which standard cron provides.
How does Dkron achieve fault tolerance?
Dkron achieves fault tolerance through several mechanisms working together. It uses a consensus protocol such as Raft for leader election, so if the leader node fails another is elected automatically. It also supports configurable job retries, stores job definitions in a distributed key-value store, and can forward jobs to other nodes when one becomes unavailable.
How do you install Dkron on Kubernetes?
You can install Dkron on Kubernetes with a Helm chart, such as the 8grams microk8s-helm-chart template. Clone the chart, create a values.yaml to override defaults, then run helm install dkron with the general chart and your namespace using create-namespace. Afterward, verify the deployment and ingress with kubectl and open the Dkron web UI.
What is Dkron used for?
Dkron is used for reliable, scalable, distributed task scheduling across multiple servers or containers, especially where fault tolerance is critical. Typical uses include scheduled order processing, payment settlements, and inventory updates in microservices architectures. It suits any workload, such as finance, healthcare, or IoT, that needs scheduled jobs to run on time without a single point of failure.
Supporter culture is shaped by chants, colours, badges, and the shirts worn on matchday as fans compare old designs with the look of newer campaigns. Discussions about retro collar designs give collectors a reason to look beyond the most recent release. When supporters think about matchday clothing, player version football shirts remains part of the discussion around teams, seasons, and supporter culture. When names and numbers matter, the shirt works as a cultural object as well as something to wear.