Ansible: The Powerful Configuration Management
By Glend Maatita
Designed to facilitate the automation of configuration management, application deployment, and task automation, Ansible has become a cornerstone of modern IT practices
Introduction
In the rapidly evolving world of IT and DevOps, automation tools have become indispensable. Among these tools, Ansible stands out for its simplicity, ease of use, and powerful capabilities. Designed to facilitate the automation of configuration management, application deployment, and task automation, Ansible has become a cornerstone of modern IT practices. This article delves into the history, architecture, core concepts, and comparisons with other tools, providing a thorough understanding of Ansible and its significance in the DevOps ecosystem.
History of Ansible
Ansible was created by Michael DeHaan in 2012. At its inception, the primary goal was to develop a simple, agentless, and flexible tool that could address the complexities and limitations of existing automation solutions. DeHaan, who had previously worked on Cobbler and Func, sought to create a tool that would be easy to use and adopt by both developers and system administrators.
Since its release, Ansible has undergone significant growth and evolution. In 2013, Ansible 1.0 was released, marking the beginning of its journey in the automation space. The following year saw the introduction of Ansible Galaxy, a community hub for sharing roles and playbooks. This was a significant milestone as it promoted collaboration and reuse within the Ansible community. In 2015, Red Hat acquired Ansible, which propelled its development and integration into enterprise environments. The acquisition by Red Hat was a strategic move that brought more resources and support to Ansible, ensuring its continued growth and adoption.
Today, Ansible is backed by a robust community and substantial corporate support. It is widely used across various industries, from small startups to large enterprises, and continues to evolve with regular updates and enhancements. Ansible's integration with Red Hat's product suite has further solidified its position as a leading automation tool. The community around Ansible has also grown, with numerous contributors constantly improving the tool and expanding its capabilities.
Why Ansible Was Created
Before Ansible, existing tools like Puppet and Chef were widely used but often criticized for their complexity and steep learning curves. Ansible was created to simplify IT automation by providing a tool that was easy to learn and use. Its agentless architecture eliminated the need for installing agents on managed nodes, reducing overhead and complexity. This approach made it more appealing to a broader audience, including those who might not have extensive experience with traditional configuration management tools.
One of the core motivations behind Ansible was to bridge the gap between developers and operations teams, facilitating better collaboration and adoption of DevOps practices. By using human-readable YAML syntax and declarative language, Ansible made it easier for both developers and sysadmins to write and understand automation scripts. This approach not only simplified the process of writing automation scripts but also made them more maintainable and easier to review.
Ansible was built with key design principles in mind: simplicity, ease of use, and flexibility. Its simplicity is one of its most appealing features. Tasks are defined in simple, human-readable YAML files, making it accessible to a wide range of users. The ease of installation and use, along with its agentless nature, makes Ansible a preferred choice for many organizations. Moreover, Ansible is highly flexible, capable of handling a wide range of automation tasks, from configuration management to application deployment and orchestration.
Ansible Architecture

Ansible's architecture is designed to be simple yet powerful, with core components that include modules, playbooks, and inventories. Modules are the building blocks of Ansible. They are small programs that perform specific tasks, such as managing packages, services, or files on a remote system. These modules can be written in any language and are executed on the managed nodes. This modular approach allows users to extend Ansible's functionality easily and tailor it to their specific needs.
Playbook
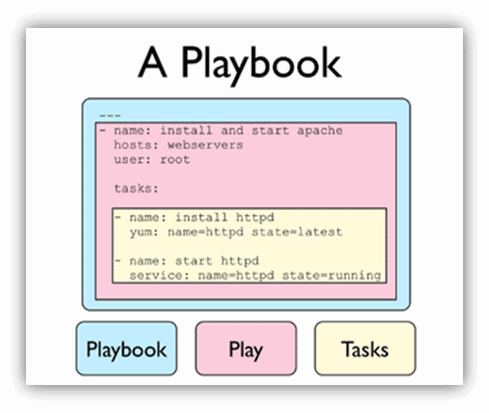
Playbooks are YAML files that define a series of tasks to be executed on managed nodes. They provide a way to organize tasks and manage complex workflows. Each playbook consists of one or more plays, which define the tasks and the hosts on which they should be executed. This structure allows for the orchestration of multiple tasks across different groups of hosts, enabling complex automation scenarios.
YAML
YAML (YAML Ain't Markup Language) is used to define Ansible playbooks. It is a human-readable data serialization standard that makes playbooks easy to write and understand. Here's a simple example of a playbook that installs and starts Apache:
- name: Install and start Apache
hosts: webservers
become: yes
tasks:
- name: Install Apache
apt:
name: apache2
state: present
- name: Ensure Apache is running
service:
name: apache2
state: startedIn this playbook, tasks are defined in a clear, readable format that specifies the desired state of the system. This makes it easy for both new and experienced users to understand and modify the playbook as needed.
Inventory
Ansible uses inventories to keep track of the hosts it manages. Inventories can be simple text files listing IP addresses or hostnames, or they can be dynamic, generated by scripts or from cloud provider APIs. This flexibility allows Ansible to manage both static and dynamic environments efficiently. For example, a static inventory might look like this:
[webservers]
web1.example.com
web2.example.com
[dbservers]
db1.example.com
db2.example.comWhile a dynamic inventory might be generated using a script that queries a cloud provider's API to list all instances matching certain criteria.
Ansible operates using a control node that orchestrates tasks on managed nodes. The execution flow typically involves writing playbooks to define the desired state and tasks in YAML format, managing inventories to list the target nodes, and running playbooks from the control node, which connects to the managed nodes via SSH (or WinRM for Windows). This execution flow ensures that tasks are executed in a controlled and predictable manner.
Agentless
One of Ansible's defining features is its agentless architecture. Unlike other tools that require agents to be installed on managed nodes, Ansible uses standard protocols like SSH for Linux/Unix systems and WinRM for Windows systems. This simplifies deployment and reduces maintenance overhead. By leveraging existing protocols, Ansible minimizes the complexity and potential points of failure associated with agent-based architectures.
Ansible supports various plugins that extend its functionality. These plugins include callback plugins, which customize output or integrate with other systems; connection plugins, which define how Ansible connects to hosts (e.g., SSH, WinRM); lookup plugins, which retrieve data from external sources (e.g., files, databases); and inventory plugins, which generate dynamic inventories from external sources. This plugin architecture allows Ansible to be highly extensible and adaptable to different environments and requirements.
Idempotency
Idempotency is a crucial concept in Ansible. It ensures that running a playbook multiple times yields the same result. This means tasks are only executed when necessary, preventing unintended changes. For example, if a package is already installed on a system, Ansible will not attempt to reinstall it, ensuring that the system's state remains consistent and predictable.

Roles
Roles provide a way to organize playbooks into reusable components. Each role contains tasks, files, templates, and variables necessary for a specific function. This modular approach simplifies complex playbooks and promotes code reuse. For example, a role for setting up a web server might include tasks for installing the web server software, deploying configuration files, and starting the service. This role can then be reused across different playbooks and projects, reducing duplication and improving maintainability.
![Understanding and Setting up Ansible Roles [Tutorial]](https://adamtheautomator.com/wp-content/uploads/2021/09/image-110.png)
Handlers
Handlers are special tasks that are triggered by other tasks using the notify directive. They are typically used for actions like restarting services only when a change occurs. For example, if a configuration file is modified, a handler can be triggered to restart the associated service to apply the changes:
- name: Install Apache
apt:
name: apache2
state: present
notify: Restart Apache
handlers:
- name: Restart Apache
service:
name: apache2
state: restartedFacts
Facts are system information gathered by Ansible from managed nodes. They provide details like operating system, IP addresses, and hardware specifications. Facts can be used in playbooks to make decisions based on the state of the managed nodes. For example, a playbook might use facts to determine the operating system type and perform different tasks based on that information:
- name: Gather facts
hosts: all
tasks:
- name: Print OS family
debug:
msg: "This system is {{ ansible_os_family }}"Variables
Variables allow customization and parameterization of playbooks. They can be defined at various levels, including playbooks, roles, and inventories. For example, you can define a variable to specify the version of a package to be installed, making it easy to change the version without modifying the playbook itself:
- name: Install specific version of Apache
hosts: webservers
vars:
apache_version: 2.4.29
tasks:
- name: Install Apache
apt:
name: "apache2={{ apache_version }}"
state: presentTemplates
Templates enable the generation of dynamic configuration files. Ansible uses the Jinja2 templating engine to replace variables and expressions within templates. For example, an Apache virtual host configuration template might look like this:
<VirtualHost *:80>
ServerName {{ server_name }}
DocumentRoot {{ doc_root }}
</VirtualHost>Tag
Tags allow selective execution of tasks within a playbook. This is useful for running specific parts of a playbook without executing the entire set of tasks. For example, you can tag tasks for installing software and starting services separately, and then run only the tasks associated with a specific tag:
- name: Install Apache
apt:
name: apache2
state: present
tags: install
- name: Ensure Apache is running
service:
name: apache2
state: started
tags: startAnsible Galaxy
Ansible Galaxy is a community hub where users can share roles and playbooks. It provides a repository of reusable roles that can be easily integrated into playbooks, promoting collaboration and code reuse. For example, you can use Ansible Galaxy to find a role for setting up a MySQL database and integrate it into your playbook:
~$ ansible-galaxy install geerlingguy.mysqlComparison with Other Tools
Ansible and Chef are both popular configuration management tools, but they have different approaches and strengths. Ansible uses a declarative approach, where the desired state is defined in YAML and Ansible ensures the system matches this state. Chef, on the other hand, uses an imperative approach, where users define the steps to achieve the desired state using Ruby-based DSL (Domain Specific Language).
| Feature | Ansible | Chef | Puppet | SaltStack |
|---|---|---|---|---|
| Configuration Management Approach | Declarative, YAML-based | Imperative, Ruby-based DSL | Declarative, Puppet DSL | Declarative, YAML-based |
| Agent Architecture | Agentless (SSH/WinRM) | Agent-based | Agent-based | Agent-based with ZeroMQ |
| Ease of Use | High, simple syntax | Medium, steeper learning curve | Medium, steeper learning curve | Medium, steeper learning curve |
| Scalability | Good, but relies on SSH connections | Good, designed for large-scale environments | Good, designed for large-scale environments | Excellent, fast and scalable with ZeroMQ |
| Community and Ecosystem | Strong, extensive modules and roles | Strong, extensive cookbooks | Strong, extensive modules | Strong, extensive modules and states |
| Extensibility | High, with custom modules and plugins | High, with custom resources and libraries | High, with custom types and providers | High, with custom modules and states |
| Use Cases | Configuration management, application deployment, orchestration | Configuration management, application deployment | Configuration management, application deployment | Configuration management, real-time event-driven automation |
Use Cases and Applications
Ansible excels in configuration management by defining infrastructure as code. For example, setting up a web server environment can be done through playbooks that ensure consistency across all servers.
Example 1: Install Nginx
Here is a detailed example of a playbook that installs and configures Nginx on a group of web servers:
- name: Configure web server
hosts: webservers
become: yes
tasks:
- name: Install Nginx
apt:
name: nginx
state: present
- name: Ensure Nginx is running
service:
name: nginx
state: started
- name: Deploy configuration
template:
src: templates/nginx.conf.j2
dest: /etc/nginx/nginx.conf
notify: Restart Nginx
handlers:
- name: Restart Nginx
service:
name: nginx
state: restartedIn this playbook, the apt module is used to install Nginx, the service module ensures that Nginx is running, and the template module deploys the Nginx configuration file. A handler is also defined to restart Nginx if the configuration file is modified.
Example 2: Deploy Python App
Ansible simplifies the deployment of applications by automating the entire process. Here is an example of deploying a Python application, including the installation of dependencies, cloning the repository, and starting the application:
- name: Deploy Python application
hosts: appservers
become: yes
tasks:
- name: Install dependencies
apt:
name: "{{ item }}"
state: present
with_items:
- python3
- python3-pip
- name: Clone repository
git:
repo: 'https://github.com/example/app.git'
dest: /opt/app
- name: Install application requirements
pip:
requirements: /opt/app/requirements.txt
- name: Start application
systemd:
name: app
enabled: yes
state: startedThis playbook demonstrates how Ansible can automate the entire application deployment process, ensuring consistency and reducing human error.
Example 3: CI/CD Pipeline
Ansible is a key player in CI/CD pipelines. It automates the process of deploying code changes, ensuring consistency and reducing human error. Integration with tools like Jenkins or GitLab CI can streamline the deployment process. Here is an example of a playbook that integrates with a CI/CD pipeline:
- name: CI/CD pipeline
hosts: all
tasks:
- name: Checkout code
git:
repo: 'https://github.com/example/app.git'
dest: /opt/app
- name: Run tests
shell: pytest /opt/app/tests
- name: Deploy application
include_role:
name: deploy_appIn this playbook, the git module is used to check out the latest code, the shell module runs tests using pytest, and the include_role directive deploys the application using a predefined role.
Example 4: Setup Policy
Ansible can automate the implementation of security policies and compliance checks. For example, applying security patches and ensuring firewall rules are in place can be automated using a playbook:
- name: Apply security patches
hosts: all
become: yes
tasks:
- name: Update all packages
apt:
upgrade: dist
- name: Ensure UFW is installed
apt:
name: ufw
state: present
- name: Configure firewall rules
ufw:
rule: allow
name: 'SSH'
port: 22This playbook updates all packages on the managed nodes, ensures that UFW (Uncomplicated Firewall) is installed, and configures a firewall rule to allow SSH traffic.
In the next article, will explore the more use case of Ansible, from simple things like deploying containerized applications to complex things like setting up Kubernetes cluster.
Frequently Asked Questions
What is Ansible?
Ansible is an open-source configuration management and automation tool that uses a declarative, YAML-based approach to define system state. It is agentless, connecting to managed machines over SSH or WinRM, so no software needs to be installed on target hosts. Ansible handles configuration management, application deployment, and orchestration.
Why is Ansible agentless?
Ansible is agentless because it connects to managed nodes over standard protocols like SSH and WinRM instead of requiring a persistent agent on each host. This lowers setup overhead, reduces maintenance, and avoids running extra services on target machines. It also simplifies security, since you manage existing SSH access rather than agent software.
Ansible vs Puppet vs Chef: what is the difference?
Ansible uses a declarative, YAML-based syntax and is agentless over SSH or WinRM, making it simple to learn. Puppet uses its own declarative DSL and an agent-based model, while Chef uses an imperative, Ruby-based DSL with agents. Ansible is often favored for ease of use; Chef and Puppet suit large, established environments.
What is Ansible used for?
Ansible is used for configuration management, application deployment, and orchestration across servers and cloud infrastructure. Teams write playbooks in YAML to describe the desired state of systems, then run them to install packages, configure services, and coordinate multi-step deployments. Its extensive library of modules and roles supports a wide range of automation tasks.
Is Ansible good for large-scale environments?
Ansible scales well for many use cases, backed by a strong community and extensive modules and roles. Because it relies on SSH connections rather than agents, very large fleets may need tuning of parallelism and connection handling. For extremely large, event-driven environments, agent-based tools like SaltStack can offer additional scalability.
Football fans often treat kit design as part of the story around a team as the design can recall players, cities, and moments that shaped a generation. Discussions about player issue details help readers think about how a team shirt fits their own use. For supporters studying famous shirt designs, Chelsea football shirt for supporters is part of the discussion around teams, seasons, and supporter culture. The history behind a kit keeps the paragraph grounded in football culture rather than simple promotion.